
Cutting down memory usage of a Haskell web app
2017-06-28
You may have heard of the Star Trek script search tool at http://scriptsearch.dxdy.name. I'm writing a similar thing for Stargate. The difference is, of course, is that my tool will be running on some crappy Amazon AWS t2.nano with no RAM.
The first prototype was written in Python, but the parsing code was always written in Haskell (Parsec is great). I decided to move everything into Haskell so there wouldn't be this redundancy of parsing in Haskell then serializing to disk then reading it from Python...one codebase for everything would be much simpler.
I wrote up a quick Haskell version, but there was one small problem when I tried to use it:
$ ./stargate-search
Setting phasers to stun... (port 5000) (ctrl-c to quit)
Killed
That's right, the OOM killer had to step in and put my app down like the sloppy wasteful piece of junk it was.
How could I fix this?
Profiling
Obviously the first step when trying to fix code is trying to work out what's wrong. I compiled my program with profiling options and ran some stress tests.
$ stack build --profile
$ stack exec -- stargate-search +RTS -p -s &
$ ./tools/stress.sh
(All stress.sh does is shoot 25 requests to the server so we can see how it runs)
The results were deeply troubling. Here are some highlights (bear in mind, all this code does is search a few dozen MB of fairly structured data).
75,013,509,424 bytes allocated in the heap
5,751,785,424 bytes copied during GC
528,085,912 bytes maximum residency (17 sample(s))
5,809,384 bytes maximum slop
1523 MB total memory in use (0 MB lost due to fragmentation)
Wow, that's really something. 75 GB allocated? That seems like a lot, but remember that the garbage collector in GHC is really good, we can afford to allocate a ton as long as we get rid of it fairly quickly.
But the 528 MB residency is concerning. Surely all of that is during the initial parse of the Stargate transcripts, right? I'd better take a look at the graph...
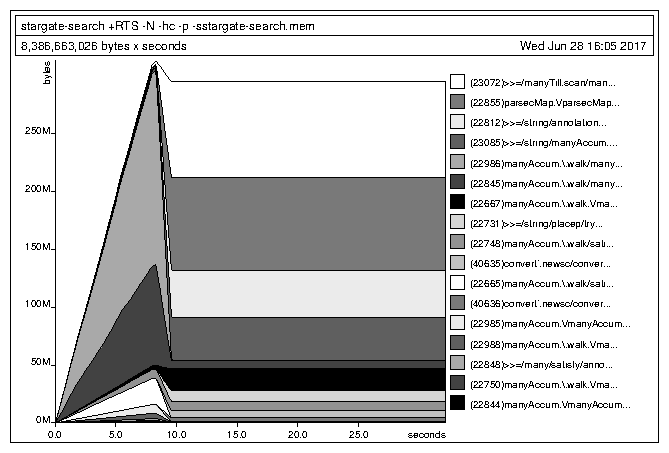
Oh...I guess the peak residency is in the parsing stage, but it doesn't go down much. Let's take a look at the cost centre breakdown to see where the low-hanging fruit is.
COST CENTRE MODULE SRC %time %alloc
match Web.Stargate.Main lib/Web/Stargate/Main.hs:95:1-87 71.3 56.4
satisfy Text.Parsec.Char Text/Parsec/Char.hs:(140,1)-(142,71) 6.0 13.0
string Text.Parsec.Char Text/Parsec/Char.hs:151:1-51 5.2 14.5
manyAccum.\.walk Text.Parsec.Prim Text/Parsec/Prim.hs:(607,9)-(612,41) 2.3 5.3
So this basically tells us that the vast majority of work is done in the string matching code. Not a surprise. Let's take a look at what that code is, exactly:
match :: String -> String -> Bool
match query body = (null query) || ((map toUpper query) `isInfixOf` (map toUpper body))
So many things wrong with this...everyone always says premature optimization is the devil, but I think I took it a bit too far in the other direction.
String is rubbish
The obvious low-hanging fruit here is String. This is for several reasons:
type String = [Char]: There is no secret optimization going on here, you get all of the downsides of O(n) access with none of the upsides of a linked list since we never do anything with the head, where everything is O(1).map toUpper query: This is blatantly inefficient. Every time we want to do a case-insensitive search, we map over the query but then throw away the result? I guess the compiler might optimize this away, but it would be smarter to upper case it before running the match function a billion times.isInfixOffromData.Listis literally implemented like this:isInfixOf needle haystack = any (isPrefixOf needle) (tails haystack). Sweet Jesus, that's the most naive implementation of anything I've ever seen. I suppose that, since this is fromData.List, no assumptions can be made about the data, so fair enough. But this is another clue that I shouldn't be usingString.
Let's get on with fixing this. Essentially, I just imported
Data.Text qualified with T at the start of every file, replaced
String with T.Text everywhere, dealt with all of the type errors
and it Just Worked.
With no further optimization, here is the memory graph for the new Text app:
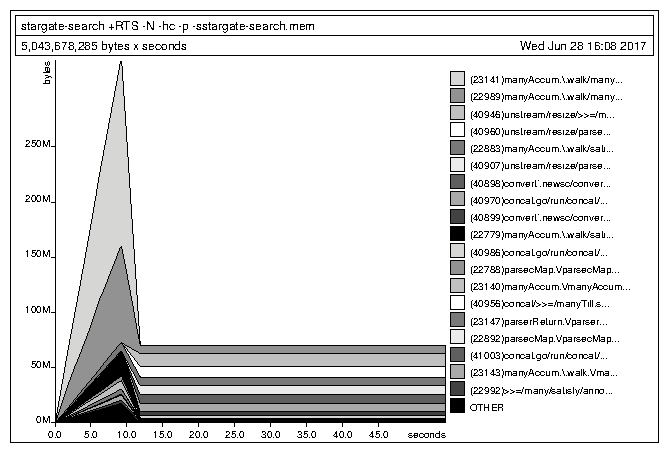
A pretty big improvement, right? But it's still pretty slow.
Highly hanging fruit
Now that the low-hanging fruit was done with, let's move on. I thought
it would improve the program if I did away with all of the inefficient
list stuff and replaced it with Data.Vector where I could. After
all, I just build these things once when parsing then access them
millions of times: the cost is in the access, which is O(1) with
Data.Vector. I also replaced some hash tables with (key, value)
vectors, since 95% of the work is iteration, and all this hashtable
stuff is unnecessarily complex for that.
So in summary, I:
- Replaced
[a]withVector awhere possible. - Replaced
HashMap a bwithVector (a,b)where it made sense.
This resulted in:
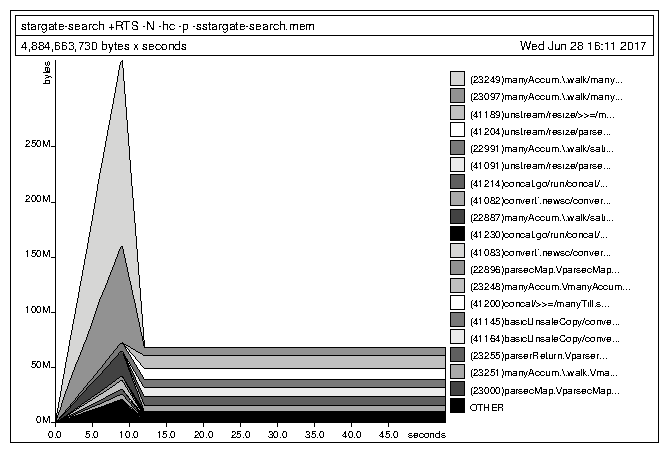
Uh, that's a bit better I guess, but not really. The execution time, in particular, is still really bad for such a simple app. The memory usage I can forgive, since the data is about that big so we need to keep it all in memory.
Writing some imperative code for more speed
At this point, I was just assuming that the RAM usage was OK (the initial parsing thing happens only once, we can just ignore it) and I set my sights on reducing the run time.
Looking at the search function, it's filled with folds and stuff. People are always saying that the unpredictability of Haskell's performance is due to laziness and inherent to the functional style, since it's so far from the metal.
So why not write an imperative-style algorithm to search? We can do
this very easily using the ST monad. For those not in the know, this
is basically the IO monad, but you can escape it.
Essentially, you can have pointers, write and read to them, modify
stuff in memory, but still have the function you write be pure. This
is done by not allowing you to use the pointers or mutable values from
one ST monad in another one, so the mutability can't leak out of
your pure function.
For example, here's a Fibonacci function that runs in constant space:
fibST :: Integer -> Integer
fibST n =
if n < 2
then n
else runST $ do
x <- newSTRef 0
y <- newSTRef 1
fibST' n x y
where fibST' 0 x _ = readSTRef x
fibST' n x y = do
x' <- readSTRef x
y' <- readSTRef y
writeSTRef x y'
writeSTRef y $! x'+y'
fibST' (n-1) x y
So I rewrote the searching function in this style. The resulting code was much easier to read, but the performance, well:
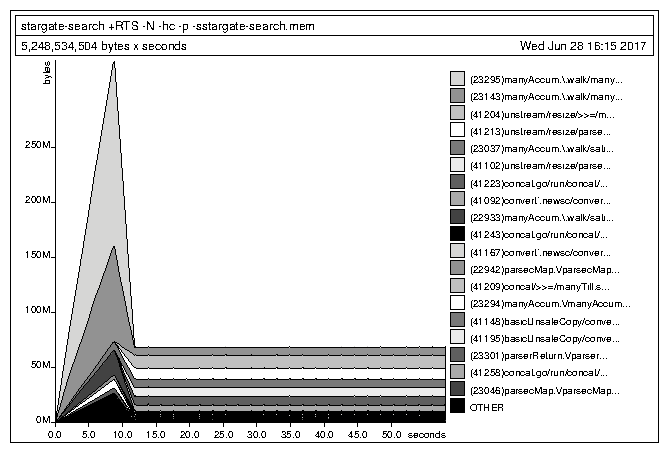
Yeah, that's right, it's worse! I guess GHC does a good job with all of those folds and stuff, better than I can do.
Remember to check all of your profiler's output
I hadn't actually looked at the profiler output for the execution time. What I saw when I did surprised me and made me facepalm a bit.
COST CENTRE MODULE SRC %time %alloc
match Web.Stargate.Search lib/Web/Stargate/Search.hs:36:1-87 41.5 30.4
caseConvert Data.Text.Internal.Fusion.Common Data/Text/Internal/Fusion/Common.hs:(398,1)-(405,45) 15.4 0.0
upperMapping Data.Text.Internal.Fusion.CaseMapping Data/Text/Internal/Fusion/CaseMapping.hs:(16,1)-(219,53) 14.2 24.8
So it turns out 24.8% of the allocations and 29.6% of the runtime of the program is spent mapping text to upper case. That's ridiculous! How didn't I see this?
So I just added a field to the transcript data structure which
contained an uppercased version, I made match use this instead of
computing it itself every time and look at the result:
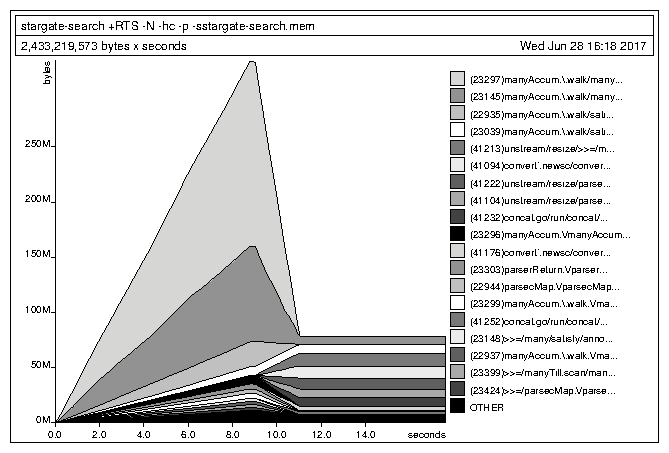
So now my program is faster. The memory usage is still bad, but that's a one-time thing. I can solve that by just switching to Attoparsec or some other actually performant parsing library.
Conclusion
Don't assume you know better than your tools: trust your profiler and compiler to tell you where you're wrong!